| 丂 |
|
丂 |
| 丂 |
Unicode 4.0 偺曗彆暥帤偺僒億乕僩 Supplementary Char |
丂 | ||
| 丂 |
|
丂 | ||
| 丂 | 偛懚抦偱偟偨偑丄Unicode 偱偼 char 偱偼廂傑傜側偄暥帤偑偁傞偙偲傪丅 Java 偱偼尵岅偑敪昞偝傟偨摉弶偐傜撪晹僐乕僪偲偟偰 Unicode 傪嵦梡偟偰偒傑偟偨丅傕偪傠傫丄char 偼 Unicode 偱暥帤偑昞偝傟傞 16 bit 偵側偭偰偄傑偟偨丅 偩偐傜丄Unicode 偲 char 偼憡惈偑偄偄偼偢側偺偱偡偑丄崱偵側偭偰 16 bit 偱偼廂傑傝傑偣傫偱偟偨偲偄傢傟偰傕... Unicode 偱摉弶峫偊傜傟偰偄偨暥帤悢傛傝傕抧媴忋偱巊傢傟傞暥帤偑慡慠懡偐偭偨偲偄偆傢偗偱偡偹丅16 bit 偵廂傑傜側偐偭偨暥帤傪曗彆暥帤 (Supplementary Character) 偲偄偄傑偡丅 曗彆暥帤偑掕媊偝傟偨偺偼 Unicode 2.0 偐傜偺傛偆偱偡偑丄幚嵺偵曗彆暥帤偑巊傢傟偨偺偼 3.1丄偦偟偰 Tiger 偱偼 Unicode 4.0 傪僒億乕僩偡傞偺偱偡丅偲偄偆偙偲偼曗彆暥帤傪僒億乕僩偡傞偙偲偼昁慠偱偡丅 偙偺栤戣偵懳偟偰 Java 偱偳偺傛偆偵曗彆暥帤傪僒億乕僩偡傞偐傪峫偊偨偺偑 JSR-204 "Java Specification Request for Unicode Supplementary Character Support" 偱偡丅 Unicode 偱偼暥帤傪偁傜傢偡偺僐乕僪億僀儞僩偲偄偆悢帤傪巊梡偟傑偡丅堦斒偵偼 U 傪巊偭偰 U+0001 偺傛偆偵偁傜傢偟傑偡丅崱傑偱偺 16 bit 偱廂傑偭偰偄偨暥帤僐乕僪偼 U+0000 偐傜 U+FFFF 偱偡丅Unicode 偱偼暥帤偺夠 (偨偲偊偽傂傜偑側偲偐) 傪柺 (Plain) 偱偁傜傢偟傑偡偑丄偙偺 U+0000 偐傜 U+FFFF 傪傑偲傔偰婎杮懡尵岅柺 (Basic Multilingual Plane) 偲屇傃傑偡丅 偙傟偵懳偟偰曗彆暥帤偼 U+10000 偐傜 U+10FFFF 偺斖埻偱偁傜傢偝傟傑偡丅 偦偆偡傞偲崲偭偨偺偼暥帤偺昞偟曽偱偡丅崱傑偱偼 16 bit 傪 8 bit 偵廂傔傞偨傔偺 UTF-8 偲 16 bit 昞尰傪偦偺傑傑巊梡偡傞 UTF-16 偑偁傝傑偟偨丅偲偙傠偑 UTF-16 傪偦偺傑傑巊偆偙偲偑偱偒側偔側偭偰偟傑偭偨傢偗偱偡丅 偦偙偱丄UTF-32 偑惂掕偝傟傑偟偨丅UTF-32 偼 32 bit 偺暥帤僐乕僪傪偦偺傑傑巊梡偟傑偡丅UTF-16 偱曗彆暥帤傪偁傜傢偡偵偼忋埵僒儘僎乕僩偲壓埵僒儘僎乕僩偵暘夝偟偰偁傜傢偡偙偲偵側傝傑偡丅 偨偲偊偽曗彆暥帤傪 16 恑偱側偔丄2 恑偱偁傜傢偡偲師偺傛偆偵側傝傑偡丅 000u uuuu xxxx xxxx xxxx xxxx 偼偠傔偺 3 bit 偼巊梡偝傟偰偄側偄偺偱丄0 偺傑傑偱偡丅巆傝偺 21 bit 傪傑偢 5 bit 偲 16 bit 偵暘妱偟傑偡丅 偙傟傪師偺傛偆偵暘夝偟傑偡丅 忋埵僒儘僎乕僩 壓埵僒儘僎乕僩 1101 10ww wwxx xxxx 1101 11xx xxxx xxxx 偙偙偱 wwww 偼 uuuuu - 1 偵側傝傑偡丅x 偺晹暘偼忋埵僒儘僎乕僩偱 6 bit丄壓埵僒儘僎乕僩偱 10 bit 傪偁傜傢偡傛偆偵側傝傑偡丅 偙傟傪 16 恑偱偁傜傢偡偲忋埵僒儘僎乕僩偼 D800 偐傜 DBFF丄壓埵僒儘僎乕僩偼 DC00 偐傜 DFFF 偑巊傢傟傑偡丅傕偲傕偲偙偺椞堟 D800 偐傜 DFFF 偼 UTF-16 偑巊梡偡傞晹暘偲偟偰暥帤偑妱傝摉偰傜傟偰偄側偄偨傔丄偙偺傛偆側巊偄曽偑偱偒傞傛偆偱偡丅 偨偲偊偽 U+10400 偼壓埵 10 bit 偑 00 0000 0000丄側傝偦偺忋偺 6 bit 偑 00 0001 偵側傝傑偡丅愭摢偺 5 bit 偑 0 0001 側偺偱 1 傪堷偔偲 0 0000 偲側傝傑偡丅偟偨偑偭偰丄 忋埵僒儘僎乕僩 1101 1000 0000 0001 = D8 01 壓埵僒儘僎乕僩 1101 1100 0000 0000 = DC 00 偲側傞傢偗偱偡丅 偝偰丄Java 偱偼偳偺傛偆偵偟偰曗彆暥帤傪偁傜傢偡偺偱偟傚偆偐丅JSR-204 傪尒偰傒傞偲丄摉弶偼偄傠偄傠側曽朄傪峫偊偨傛偆偱偡丅偨偲偊偽丄char 傪 16 bit 偐傜 32 bit 偵曄峏偟偰偟傑偆偲偄偆埬丅尵岅揑偵偼偙傟偑堦斣僔儞僾儖側曽朄偩偲巚偆偺偱偡偑丄偙傟傪偡傞偲婛懚偺 Java 偺僾儘僌儔儉偲偺僐儞僷僠價儕僥傿偑庢傟傑偣傫丅 Java 偑弌偰偒偨偲偒偵偼偟偑傜傒傕側偵傕側偐偭偨偺偱丄偙傫側偙偲偼峫偊側偔偰傕傛偐偭偨偺偱偟傚偆偑丄10 擭傕偨偭偰偙傟偩偗儊僕儍乕偵側偭偰偟傑偆偲偦偆傕偄偒傑偣傫丅 偲偄偆偙偲偱寢嬊棊偪拝偄偨偺偑師偺傛偆側曽朄偱偡丅
偙偺曽恓偵偦偭偰 API 偑傾僢僾僨乕僩偝傟偰偄傑偡丅師復偱偼偦偺偁偨傝偐傜尒偰偄偔偙偲偵偟傑偟傚偆丅
|
丂 |
| 丂 |
|
丂 | |||||||||
| 丂 | 傑偢偼偠傔偼掅儗儀儖 API 偱巊梡偝傟傞僐乕僪億僀儞僩傪巊偭偰傒傑偟傚偆丅 尒傟側偔偰偼偟傚偆偑側偄偺偱丄弌椡偡傞偙偲偐傜傗偭偰傒傑偡丅偟偐偟丄僐乕僪億僀儞僩偼 int 側偺偱偨偲偊偽扨偵 System.out.prinln(codePoint); 偺傛偆偵偟偰傕悢帤偑弌椡偝傟偰偟傑偄傑偡丅 偦偙偱丄Formatter 僋儔僗傪巊梡偟偰僐乕僪億僀儞僩傪埖偆傛偆偵偟傑偡丅
捈愙 Formatter 僋儔僗偼巊梡偟偰偄傑偣傫偑丄format 儊僜僢僪偼棤偱 Formatter 傪巊梡偟偰偄傑偡丅
捠忢丄僐乕僪億僀儞僩傪偁傜傢偡偵偼側傞傋偔 codePoint 偲偄偆柤慜偵偟偰偍偄偨傎偆偑偄偄偲巚偄傑偡丅彂幃偺拞偱 %c 傪巊梡偟偰偄傑偡偑丄%c 偼崱傑偱偺 char 偱傕 int 偱傕埖偊傞傛偆偵側偭偰偄傑偡丅char 偺応崌偼婎杮懡尵岅柺偺暥帤丄int 偱偁傟偽曗彆暥帤傕娷傫偩僐乕僪億僀儞僩偲夝庍偝傟偰偄傞傛偆偱偡丅 Character.UnicodeBlock 僋儔僗偼 Unicode 偑偳偺傛偆側暥帤傪偁傜傢偟偰偄傞偐傪偁傜傢偡偨傔偺僋儔僗偱偡丅偨偲偊偽傂傜偑側偱偁傟偽 Character.UnicodeBlock.HIRAGANA 偲掕媊偝傟偰偄傑偡丅偁傞暥帤偑偳偺傛偆側僽儘僢僋偵懏偟偰偄傞偐傪挷傋傞偵偼 Character.UnicodeBlock#of 儊僜僢僪傪巊梡偟傑偡丅int 偲 char 偺椉曽偑堷悢偲偟偰棙梡偱偒傑偡丅 偝偰丄幚峴偟偰傒傑偟傚偆丅
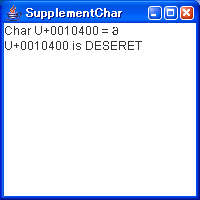
U+10400 偑 DESERET 偲偄偆僽儘僢僋偱偁傞偙偲偼暘偐傞偺偱偡偑丄娞怱偺暥帤偑暥帤壔偗偟偰偟傑偭偰偄傑偡丅偙傟偼 Windows 偵偙偺僽儘僢僋偵懳墳偡傞僼僅儞僩偑側偄偐傜偱偡丅 昞帵偱偒側偄偲偙傑偭偰偟傑偄傑偡偹丅偲偙傠偑 Tiger 偱偼僼僅儞僩偺埖偄傕曄傢偭偰偍傝丄jre/lib/fonts/fallback 偲偄偆僨傿儗僋僩儕偵僼僅儞僩傪抲偔偲丄Java2D 偺昤夋偱偙偙偵抲偐傟偨僼僅儞僩傪帺摦揑偵巊梡偟偰偔傟傞傛偆偵側偭偰偔傟偰偄傑偡丅 曗彆暥帤傪娷傫偩僼僅儞僩偱偡偑丄James Kass 偑僼儕乕偱採嫙偟偰偄傞 Code2001 偲偄偆僼僅儞僩偑偁傝傑偡丅偙傟傪巊偭偰傒傑偟傚偆丅僟僂儞儘乕僪偟偰丄ZIP 僼傽僀儖傪夞摎偡傞偲 True Type 僼僅儞僩偺 CODE2001.TTF 偲偄偆僼傽僀儖偑惗惉偝傟傞偺偱丄偙傟傪 jre/lib/fonts/fallback 偵僐僺乕偟傑偡丅fallback 偲偄偆僨傿儗僋僩儕偼僨僼僅儖僩偱偼懚嵼偟側偄偺偱丄嶌惉偟偰抲偄偰偔偩偝偄丅 偦傟偱偼丄愭傎偳偺僾儘僌儔儉傪 Java2D 傪巊梡偡傞傛偆偵曄峏偟偰傒傑偡丅Java2D 偲偄偆偲偳偺傛偆偵曄峏偡傟偽傛偔暘偐傜側偄偐傕偟傟傑偣傫偑丄扨偵 AWT 傗 Swing 偱暥帤傪昞帵偝偣傟偽偄偄偩偗偱偡丅
暥帤偺昤夋偵偼 JTextArea 僋儔僗傪巊梡偟偰偄傑偡丅
愭傎偳偼 PrintStream#format 儊僜僢僪傪巊梡偟傑偟偨偑丄暥帤楍傪嶌惉偡傞偺偱 String#format 儊僜僢僪傪巊梡偟傑偟偨丅 偙傟傪幚峴偡傞偲丄師偺傛偆側僼儗乕儉偑昞帵偝傟傑偡丅
偲偙傠偱 U+10400 偑偁傜傢偟偰偄傞曃旝暘偺儅乕僋偺傛偆側暥帤偼 DESERET 偱偁傜傢偝傟偰偄傞傛偆偵丄Deseret Alphabet 偲屇偽傟偰偄傞傕偺傜偟偄偱偡丅偙傟偼儐僞廈偺 Deseret University (尰 Utah University) 偱峫埬偝傟偨傕偺偩偦偆偱偡丅
|
丂 |
| 丂 |
|
丂 | ||||||
| 丂 | int 宆偱僐乕僪億僀儞僩偼偁傜傢偣傞偙偲偼暘偐傝傑偟偨偑丄偙傟傪 UTF-16 偵曄姺偱偒側偗傟偽巊偄暔偵側傝傑偣傫丅
1 暥帤扨埵偺曄姺偵偼 Character#toChars 儊僜僢僪傪巊梡偟傑偡丅
char 偺攝楍偵側偭偰偟傑偆偲丄偳偙偑忋埵僒儘僎乕僩偱偳偙偑壓埵僒儘僎乕僩偐暘偐傝偵偔偔側偭偰偟傑偄傑偡丅偦偙偱丄忋埵僒儘僎乕僩偐壓埵僒儘僎乕僩偐傪挷傋傞偨傔偺儊僜僢僪傕梡堄偝傟偰偄傑偡丅
Character#isHighSurrogate 儊僜僢僪偑忋埵僒儘僎乕僩偐偳偆偐傪挷傋傞儊僜僢僪丄Character#isLowSurrogate 儊僜僢僪偑壓埵僒儘僎乕僩偐偳偆偐傪挷傋傞儊僜僢僪偱偡丅 1 暥帤偱偼側偔偰丄暋悢偺暥帤傪僐乕僪億僀儞僩偱昞偟偰偄傞応崌偼 String 僋儔僗傪巊梡偟傑偡丅String 僋儔僗偺僐儞僗僩儔僋僞偵 int 偺攝楍傪庢傞傕偺偑捛壛偝傟偨偺偱丄偦傟傪巊梡偟傑偡丅
幚峴偡傞偲丄嵟屻偺僟僀傾儘僌偼僐儅儞僪僾儘儞僾僩偵偼埲壓偺傛偆偵弌椡偝傟傑偟偨丅
摉偨傝慜偱偡偑丄偨偩偟偔 U+10400 偑 D801 偲 DC00 偵暘夝偝傟偰偄傞偺偑妋擣偱偒傑偡丅 忋埵僒儘僎乕僩偐壓埵僒儘僎乕僩偐偼帺暘偱挷傋傞偺傕娙扨側偺偱偡偑丄採嫙偝傟偰偄傞傕偺傪巊偭偨傎偆偑僾儘僌儔儉偑尒傗偡偔側傝傑偡偹丅
|
丂 |
| 丂 |
|
丂 | ||||||||||||||||||||||
| 丂 | 崱搙偼媡偵 char 偐傜僐乕僪億僀儞僩傊曄姺偟偰傒傑偟傚偆丅
僐乕僪億僀儞僩傊偺曄姺偵偼 Character#toCodePoint 儊僜僢僪傪巊梡偟傑偡丅
toCodePoint 儊僜僢僪偺堷悢偼 char 偑 2 偮偵側傝傑偡丅婎杮懡尵岅柺偺暥帤偺応崌偼扨偵忋埵僒儘僎乕僩傪 0 偵偡傟偽偄偄傛偆偱偡丅 拲堄偑昁梫側偺偼丄偙偺儊僜僢僪偼扨偵悢抣寁嶼傪偟偰偄傞偩偗偱丄偦偺寢壥偑惓偟偄僐乕僪億僀儞僩偵側偭偰偄傞偐偳偆偐偼僠僃僢僋偟偰偄側偄偲偄偆偙偲偱偡丅 傕偟丄偙偺僠僃僢僋偑昁梫側応崌偼 Character#isSurrogatePair 儊僜僢僪傪巊梡偟傑偡丅 暋悢暥帤傪 int 偺攝楍偵偡傞偨傔偺儊僜僢僪偼梡堄偝傟偰偄側偄傛偆偱偡丅傕偟偐偡傞偲尒摝偟偰偄傞偐傕偟傟傑偣傫丅傕偟丄尒摝偟偰偄傞傛偆偱偟偨傜烴掚傑偱儊乕儖偟偰偔偩偝偄丅 偝偰丄String 僋儔僗偼僐乕僪億僀儞僩傪巊梡偟偨 int 偺攝楍偱傕丄UTF-16 偺僔乕働儞僗偲偟偰偺 char 偺攝楍偱傕惗惉偡傞偙偲偑偱偒傑偡丅偙偺 2 偮偺曽朄偱惗惉偝傟偨暥帤楍偼壥偨偟偰摨偠撪梕傪曐帩偟偰偄傞偺偱偟傚偆偐丅
偙傟傪幚峴偟偰傒傞偲 true 偑弌椡偝傟傞偺偱丄摨偠側偺偱偟傚偆丅
幚嵺偵 String 僋儔僗偱偼撪晹偱偳偺傛偆偵暥帤傪曐帩偟偰偄傞偺偱偟傚偆偐丅String 僋儔僗偼崅儗儀儖側 API 偵側傞偺偱 UTF-16 僔乕働儞僗傪曐帩偟偰偄傞偼偢偱偡丅 String.java 傪尒偰傒傞偲妋偐偵 UTF-16 偱曐帩偟偰偄傞傛偆偱偡丅偨偲偊偽丄char[] 偺堷悢傪偲傞僐儞僗僩儔僋僞傪尒偰傒傞偲丄
僾儘僷僥傿 value 偱 UTF-16 僔乕働儞僗傪帩偭偰偄傞傛偆偱偡丅 暋悢偺暥帤傪 int 偺攝楍偵曄姺偡傞偙偲偼偱偒側偄傛偆偱偡偑丄暥帤楍偺擟堄偺暥帤傪僐乕僪億僀儞僩偵曄姺偡傞偙偲偼偱偒傑偡丅String#codePointAt 儊僜僢僪傕偟偔偼 Character#codePointAt 儊僜僢僪傪巊梡偟傑偡丅 傑偨丄1 暥帤慜傪僐乕僪億僀儞僩偵偡傞 String#codePointBefore 儊僜僢僪丄Character#codePointBefore 儊僜僢僪偲偄偆偺傕偁傝傑偡丅
String#codePointAt 儊僜僢僪偺堷悢偼僀儞僨僢僋僗偱偡偑丄偙傟偼 char 偺攝楍偺僀儞僨僢僋僗側偺偱偟傚偆偐丄偦傟偲傕暥帤偺僀儞僨僢僋僗側偺偱偟傚偆偐丄帋偟偰傒傑偟傚偆丅
偙傟傪幚峴偟偰傒傑偟偨丅
偳偆傗傜丄char 攝楍偺僀儞僨僢僋僗偺傛偆偱偡丅傑偨丄偙偙偐傜暘偐傞偙偲偲偟偰 codePointAt 儊僜僢僪偼僀儞僨僢僋僗偑忋埵僒儘僎乕僩偺埵抲偱偁傟偽惓偟偔僐乕僪億僀儞僩偵曄姺偟偰偔傟傞偺偱偡偑丄壓埵僒儘僎乕僩偺応崌偼偦偺傑傑偦偺僀儞僨僢僋僗偺抣偵側偭偰偟傑偆偲偄偆偙偲偱偡丅 摨條偵 CodePointBefore 儊僜僢僪傕僀儞僨僢僋僗偑忋埵僒儘僎乕僩偱偁傟偽偄偄偺偱偡偑丄壓埵僒儘僎乕僩偺応崌偼 1 偮慜偺壓埵僒儘僎乕僩傪栠偟偰偔傞偲偄偆偙偲偱偡丅 尩枾偵峴偆偺偱偁傟偽丄僀儞僨僢僋僗偑帵偟偰偄傞暥帤偑忋埵僒儘僎乕僩偐偳偆偐傪挷傋側偔偰偼偄偗側偄傛偆偱偡丅 偙偙偱傆偲偟偨媈栤偑丅崱傑偱暥帤楍偺挿偝偼 char 攝楍偺挿偝偩偭偨偺偱偡偑丄曗彆暥帤傪僒億乕僩偟偨傜挿偝偼偳偆側偭偰偄傞偺偱偟傚偆偐丅偙傟傕帋偟偰傒傑偟傚偆丅
幚峴偡傞偲...
偁傝傖傝傖丄攝楍偺挿偝偵側偭偰偄傑偡丅偙傟偱偼杮摉偺暥帤悢偑傢偐傝傑偣傫丅崲偭偨丅 傛偔扵偟偰傒偨傜丄codePointCount 偲偄偆儊僜僢僪偑偁傝傑偟偨丅偙傟傪巊偆傛偆偱偡丅
偙偺応崌偼惓偟偔 11 偲側傝傑偟偨丅
曗彆暥帤偲偦傟埲奜偺暥帤偑傑偞偭偰偄偨傜偳偆側傞偺偱偟傚偆偐丅偙傟傕帋偟偰傒傑偟傚偆丅
偝偰丄偪傖傫偲暥帤悢偑弌椡偱偒傞偱偟傚偆偐?
惓偟偔暥帤悢偑弌椡偝傟傑偟偨丅 偲偄偆偙偲偼丄崱屻偼暥帤悢傪挷傋傞偲偒偼 length 儊僜僢僪偱偼側偔 codePointCount 儊僜僢僪傪巊傢側偔偰偼偄偗側偄偲偄偆偙偲偵側傝傑偡丅 偙傟偼偐側傝廳梫側 Idiom 偵側傝偦偆偱偡丅 崲偭偨偙偲偵摨偠傛偆側偙偲偼 substring 側偳偵傕偁偰偼傑傝傑偡丅substring 側偳偺堷悢偼僐乕僪億僀儞僩傪擣幆偟偰偔傟偢丄偄傑傑偱偲摨偠傛偆偵 char 偺攝楍偺僀儞僨僢僋僗偲側偭偰偟傑偄傑偡丅偳偆偵偐側傜側偄傕偺偱偟傚偆偐丅 偄偪偄偪僒儘僎乕僩偐偳偆偐傪挷傋側偔偰偼偄偗側偄偺偼寢峔柺搢偱偡丅
|
丂 |
| 丂 |
|
丂 | ||
| 丂 | 崱傑偱偼 String 僋儔僗偱帋偟偰偒傑偟偨偑丄StringBuffer/StringBuilder 僋儔僗偱偼偳偆偱偟傚偆偐丅 堦斣偺栤戣偼僐乕僪億僀儞僩傪傾儁儞僪偡傞偲偒偱偡丅僐乕僪億僀儞僩偼 int 側偺偱偦偺傑傑 append 儊僜僢僪傪巊梡偡傞偲丄扨偵悢帤偲偟偰擣幆偝傟偰偟傑偄傑偡丅 偙偺偨傔丄appendCodePoint 儊僜僢僪偑怴偨偵掕媊偝傟傑偟偨丅 偟偐偟丄憓擖偺曽偼僐乕僪億僀儞僩傪埖偆儊僜僢僪偼側偄傛偆偱偡丅偟偐偨側偄偺偱丄堦搙 char 偺攝楍偵捈偡偐丄String 僋儔僗側偳偺 CarSequence 僀儞僞僼僃乕僗偺幚憰僋儔僗傪巊梡偡傞偟偐側偝偦偆偱偡丅
|
丂 |
| 丂 |
|
丂 | ||
| 丂 | 曗彆暥帤傪僒億乕僩偡傞偙偲偵傛偭偰曄峏偑偁偭偨僋儔僗偑偄偔偮偐偁傝傑偡丅 怴婯偺僋儔僗偲偟偰偼 java.util.Formatter 僋儔僗偑偁傝傑偡丅int 傪 %c 偱弌椡偡傞偲丄僐乕僪億僀儞僩偲偟偰擣幆偝傟傑偡丅偙傟偼偡偱偵慜弎偟偨僒儞僾儖偺 SupplementaryCharTest1 僋儔僗偱巊偭偰偄傑偡丅 偦偺傎偐偵偼惓婯昞尰偑曗彆暥帤偵懳墳偝傟偰偄傑偡丅java.util.regex.Pattern/Matcher 僋儔僗偩偗偱側偔丄撪晹揑偵偙傟傜偺僋儔僗傪巊梡偟偰偄傞僋儔僗偱傕摨偠偱偡丅偐偲偄偭偰丄摿偵巊偄曽偵堘偄偼偁傝傑偣傫丅 拲堄偟側偔偰偼側傜側偄偺偑丄僾儘僷僥傿僼傽僀儖側偳偱偡丅僾儘僷僥傿僼傽僀儖偼擔杮岅側偳傪儐僯僐乕僪僔乕働儞僗 (\uXXXX 偱偁傜傢偝傟傞傕偺偱偡) 傪巊偭偰偁傜傢偟傑偡丅偙偙偱埖偊傞偺偼 UTF-16 偱偡丅UTF-32 偼巊梡偱偒傑偣傫丅 傕偪傠傫丄僾儘僷僥傿僼傽僀儖傪 XML 偱彂偔応崌偼暥帤僐乕僪傪巜掕偱偒傞偺偱丄擟堄偺暥帤僐乕僪傪巊梡偟偰婰弎偡傞偙偲偑偱偒傑偡丅
|
丂 |
| 丂 |
|
丂 | ||
| 丂 | 曗彆暥帤側傫偰娭學側偄偲巚偭偰偄傑偣傫偐丅幚偼堦晹偺娍帤傕曗彆暥帤偵擖偭偰偄傑偡丅CJK Unified Ideographs Extension 側偳偑偦傟偵憡摉偟傑偡丅懠恖帠偱偼側偄偲偄偆偙偲側傫偱偡丅 曗彆暥帤偑僒億乕僩偝傟偰丄傾僾儕働乕僔儑儞偼塭嬁傪偆偗傞偺偱偟傚偆偐丅Java 僾儔僢僩僼僅乕儉偵偍偗傞曗彆暥帤偺僒億乕僩 偲偄偆僪僉儏儊儞僩偵偼傾僾儕働乕僔儑儞傪 3 偮偺僞僀僾偵暘偗偰偄傑偡丅
1 偺僞僀僾偺傾僾儕働乕僔儑儞偱偼堦斒揑偵曄峏偡傞昁梫偼偁傝傑偣傫丅 2 偺僞僀僾偺傾僾儕働乕僔儑儞偱偼屄乆偺暥帤偑桳岠偐偳偆偐挷傋傞昁梫偑偁傝傑偡丅偨偩偟丄曄峏偡傞壜擻惈偼偁傑傝偁傝傑偣傫丅 栤戣偼 3 偺僞僀僾偺傾僾儕働乕僔儑儞偱偡丅偙偺僞僀僾偺傾僾儕働乕僔儑儞偼屄乆偺暥帤傪挷傋傞偺偼摉偨傝慜偱偡偑丄曗彆暥帤偺応崌偼 int 偺僐乕僪億僀儞僩偵曄姺偟偰埖偆昁梫偑偁傞偐傕偟傟傑偣傫丅 偱傕丄僐乕僪億僀儞僩偲 UTF-16 傪崿偤偰巊偆偺偼偄傑偄偪偡偭偒傝偟傑偣傫丅傗偭傁傝巇條揑偵偡偭偒傝偡傞偺偼 char 傪 32 bit 偵偡傞偙偲偩偲巚偆偺偱偡偑丄偙傟偼偄傠偄傠偲栤戣偑偁傞偺偱偟偐偨側偄偺偱偟傚偆丅
崱夞巊梡偟偨僒儞僾儖偼偙偙偐傜僟僂儞儘乕僪偱偒傑偡丅
嶲峫
(Jun. 2004) |
丂 |
| 丂 |
|
丂 |