僗僩儕乕儈儞僌偱 XML - StAX
戞 3 偺巋媞?
崱傑偱丄Java 偱 XML 傪埖偆偺偵偼 3 庬椶偺曽朄偑偁傝傑偟偨丅
- DOM
- SAX
- JAXB
JAXB 偼偪傚偭偲栄怓偑堘偆偺偱丄扨偵 XML 傪僷乕僗偡傞側傜偽 DOM 偐 SAX 偱偡丅
偲偙傠偑丄Java SE 6 偱偼怴偨偵傕偆 1 偮僷乕僒偑捛壛偝傟傑偟偨丅
偦傟偑崱夞徯夘偡傞 Streaming API for XML丄捠徧 StAX 偱偡丅StAX 偼 JCP 偺 JSR-173 偱嶔掕偝傟偰偍傝丄BEA 偑僗儁僢僋儕乕僪偵側偭偰偄傑偡丅
偝偰丄偙偺 3 偮偺僷乕僒偺堘偄偲偄偆偺偼壗側偺偱偟傚偆丅傛偔愢柧偝傟傞偺偑丄
- DOM - 僆僽僕僃僋僩儌僨儖
- SAX - 僾僢僔儏儌僨儖
- StAX - 僾儖儌僨儖
偲偄偆傕偺偱偡丅
DOM 偑僆僽僕僃僋僩儌僨儖偲偄偆偺偼偡偖偵暘偐傝傑偡偹丅DOM 僣儕乕偲偟偰僸乕僾偵帩偮傢偗偱偡偐傜丅
暘偐傜側偄偺偑僾僢僔儏偲僾儖偱偡丅
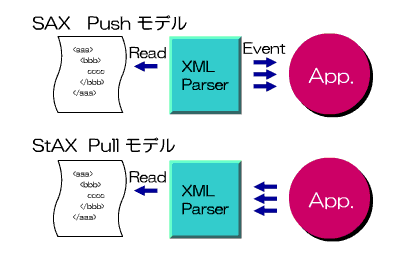
偳偆傗傜丄僾僢僔儏偲偄偆偺偼堦曽揑偵僷乕僒偑僷乕僗傪偟偰偄傞傾僾儕働乕僔儑儞傪屇傃弌偡傛偆側僀儊乕僕偱偡丅傛偆偡傞偵僀儀儞僩偱偡偹丅
SAX 僷乕僒偼 XML 僪僉儏儊儞僩傪摢偐傜撉傫偱偄偒丄僞僌偺奐巒傗廔椆側偳偵傇偮偐傞偲丄寛傔傜傟偨傾僾儕働乕僔儑儞懁偺僐乕儖僶僢僋儖乕僠儞傪僐乕儖偡傞傢偗偱偡丅
傾僾儕働乕僔儑儞懁偼 XML 僪僉儏儊儞僩偺撉傒崬傒偺惂屼傪偍偙側偆偙偲偼偱偒偢丄僐乕儖僶僢僋儖乕僠儞偱岥傪奐偗偰懸偭偰偄傞偩偗偱偡丅
StAX 偼媡偵 XML 僪僉儏儊儞僩偺撉傒崬傒偺惂屼傪傾僾儕働乕僔儑儞懁偑偍偙側偄傑偡丅偦偟偰丄昁梫偵墳偠偰 StAX 僷乕僒偐傜忣曬傪庢摼偡傞傛偆側峔惉偵側傝傑偡丅
偦偺偨傔丄SAX 偑僾僢僔儏丄StAX 偑僾儖偲屇偽傟傞偺偱偟傚偆丅
偦傟偵偟偰傕 StAX 偺僱乕儈儞僌偱偡偑丄柧傜偐偵 SAX 傪堄幆偟偰偄傑偡偹 ^^;;
慜抲偒偑挿偔側偭偰偟傑偄傑偟偨丅僾儖儌僨儖偺 StAX 傪偳偆偄偆傆偆偵巊偊偽偄偄偺偐丄尒偰偄偒傑偟傚偆丅
偲傝偁偊偢僷乕僗 - Cursor API 曇
StAX 偵偼 2 庬椶偺曽朄偱僷乕僗傪偡傞偙偲偑偱偒傑偡丅堦曽偑 Cursor API 偱丄傕偆堦曽偑 Event Iterator API 偱偡丅
巊偄曽偺婎杮揑側巚憐偼摨偠側偺偱偡偑丄儊僜僢僪側偳偺拪徾搙偑堘偭偰偄傑偡丅Event Iterator API 偺曽偑拪徾搙偑崅偔側偭偰偄傑偡丅
偲偼偄偭偰傕丄椉曽巊偄偙側偣偨曽偑偄偄偺偱丄傑偢偼 Cursor API 偐傜丅
| 僒儞僾儖偺僜乕僗僐乕僪 | StAXSample1.java |
|---|
StAX 偼偦偺柤偺捠傝僗僩儕乕儉傪巊偭偰僷乕僗傪偟傑偡丅偦偺僗僩儕乕儉傪昞偡僋儔僗偑 javax.xml.stream.XMLStreamReader 僋儔僗偱偡丅
XMLStreamReader 僆僽僕僃僋僩傪惗惉偡傞偵偼丄javax.xml.script.XMLInputFactory 僋儔僗偺 createXMLStreamReader 儊僜僢僪傪巊梡偟傑偡丅
createXMLStreamReader 儊僜僢僪偼堷悢偺堎側傞傕偺偑壗庬椶偐偁傝傑偡偑丄偙偙偱偼 InputStream 僋儔僗傪巊梡偡傞傕偺傪巊偭偰偄傑偡丅
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamReader;
import javax.xml.stream.XMLStreamException;
public class StAXSample1 {
public StAXSample1(String xmlfile) throws FileNotFoundException, XMLStreamException {
XMLInputFactory factory = XMLInputFactory.newInstance();
BufferedInputStream stream = new BufferedInputStream(new FileInputStream(xmlfile));
XMLStreamReader reader = factory.createXMLStreamReader(stream);
for (; reader.hasNext(); reader.next()) {
int eventType = reader.getEventType();
if (eventType == XMLStreamConstants.START_ELEMENT) {
System.out.println("Name: " + reader.getName());
}
}
reader.close();
}
public static void main(String[] args) throws FileNotFoundException, XMLStreamException {
new StAXSample1(args[0]);
}
}
XMLStreamReader 僆僽僕僃僋僩偑惗惉偱偒偨傜丄屻偼 Iterator 僀儞僞僼僃乕僗偲摨偠傛偆偵巊梡偟傑偡丅
傑偢丄hasNext 儊僜僢僪偱僀儀儞僩偑偁傞偐偳偆偐傪挷傋傑偡丅
偦偟偰丄僀儀儞僩偺庬椶傪挷傋偰丄偦傟偵墳偠偰昁梫側忣曬傪庢摼偟傑偡丅
偦偟偰丄next 儊僜僢僪傪巊梡偟偰師偺僀儀儞僩偵堏摦偟傑偡丅
偙偺僀僥儗乕僔儑儞儖乕僾偲 XMLStreamReader 僆僽僕僃僋僩偐傜忣曬傪庢摼偡傞偲偙傠偑丄僾儖偺摿挜偱偡偹丅
偙偺椺偱偼 hasNext 儊僜僢僪傪僐乕儖偟偨屻丄僀儀儞僩偺庬椶偑 "僞僌偺奐巒" 偱偁傟偽僞僌偺柤慜傪弌椡偡傞偲偄偆張棟傪偍偙側偭偰偄傑偡丅
偙偺僒儞僾儖偱偙偺僪僉儏儊儞僩 (偮傑傝 stax.html 偱偡偹) 傪僷乕僗偟偰傒傑偡丅偙偺僪僉儏儊儞僩偼 XHTML 偱婰弎偝傟偰偄傞偺偱丄僷乕僗偱偒傞偼偢偱偡丅
C:\temp>java StAXSample1 stax.html
Name: {http://www.w3.org/1999/xhtml}html
Name: {http://www.w3.org/1999/xhtml}head
Name: {http://www.w3.org/1999/xhtml}title
Name: {http://www.w3.org/1999/xhtml}meta
Name: {http://www.w3.org/1999/xhtml}meta
Name: {http://www.w3.org/1999/xhtml}link
Name: {http://www.w3.org/1999/xhtml}body
Name: {http://www.w3.org/1999/xhtml}div
Name: {http://www.w3.org/1999/xhtml}p
Name: {http://www.w3.org/1999/xhtml}h1
Name: {http://www.w3.org/1999/xhtml}h2
Name: {http://www.w3.org/1999/xhtml}p
Name: {http://www.w3.org/1999/xhtml}ul
Name: {http://www.w3.org/1999/xhtml}li
......
挿偔側傞偺偱埲壓徣棯丅
{ } 偱埻傑傟偰偄傞偺偑柤慜嬻娫偱丄偦偺屻偵僞僌柤偑昞帵偝傟偰偄傑偡丅偲偄偆偺傕 getName 儊僜僢僪偺栠傝抣偼 QName 僆僽僕僃僋僩偩偐傜偱偡偹丅
傕偪傠傫丄僞僌柤埲奜偺忣曬傕庢摼偱偒傑偡丅
| 僒儞僾儖偺僜乕僗僐乕僪 | StAXSample2.java |
|---|
for (; reader.hasNext(); reader.next()) {
int eventType = reader.getEventType();
if (eventType == XMLStreamConstants.START_ELEMENT) {
System.out.println("Name: " + reader.getName());
System.out.println("Local Name: " + reader.getLocalName());
System.out.println("Prefix: " + reader.getPrefix());
System.out.println("Attribute:");
int count = reader.getAttributeCount();
System.out.println(" Count: " + count);
for (int i = 0; i < count; i++) {
System.out.println(" Name: " + reader.getAttributeName(i));
System.out.println(" Local Name: " + reader.getAttributeLocalName(i));
System.out.println(" Namespace: " + reader.getAttributeNamespace(i));
System.out.println(" Type: " + reader.getAttributeType(i));
System.out.println(" Value: " + reader.getAttributeValue(i));
}
System.out.println("Namespace:");
System.out.println(" URI: " + reader.getNamespaceURI());
count = reader.getNamespaceCount();
System.out.println(" Count: " + count);
for (int i = 0; i < count; i++) {
System.out.println(" Prefix: " + reader.getNamespacePrefix(i));
System.out.println(" URI: " + reader.getNamespaceURI(i));
}
System.out.println();
}
}
挿偄偺偱丄for 暥偺拞偩偗帵偟傑偡丅
偙傟偩偗偲傟傟偽丄偨偄偰偄偺偙偲偼偲傟傑偡丅
幚峴偟偰傒傞偲丄師偺傛偆偵側傝傑偟偨丅
C:\temp>java StAXSample2 stax.html
Name: {http://www.w3.org/1999/xhtml}html
Local Name: html
Prefix:
Attribute:
Count: 0
Namespace:
URI: http://www.w3.org/1999/xhtml
Count: 1
Prefix: null
URI: http://www.w3.org/1999/xhtml
Name: {http://www.w3.org/1999/xhtml}head
Local Name: head
Prefix:
Attribute:
Count: 0
Namespace:
URI: http://www.w3.org/1999/xhtml
Count: 0
Name: {http://www.w3.org/1999/xhtml}title
Local Name: title
Prefix:
Attribute:
Count: 0
Namespace:
URI: http://www.w3.org/1999/xhtml
Count: 0
Name: {http://www.w3.org/1999/xhtml}meta
Local Name: meta
Prefix:
Attribute:
Count: 2
Name: http-equiv
Local Name: http-equiv
Namespace: null
Type: CDATA
Value: Content-Type
Name: content
Local Name: content
Namespace: null
Type: CDATA
Value: text/html; charset=shift_jis
Namespace:
URI: http://www.w3.org/1999/xhtml
Count: 0
Name: {http://www.w3.org/1999/xhtml}meta
Local Name: meta
Prefix:
Attribute:
Count: 2
Name: name
Local Name: name
Namespace: null
Type: CDATA
Value: keywords
Name: content
Local Name: content
Namespace: null
Type: CDATA
Value: Java SE 6, Java SE 6, StAX, Streaming API for XML
Namespace:
URI: http://www.w3.org/1999/xhtml
Count: 0
......
挿偔側傞偺偱埲壓徣棯丅
偝偰丄偙偙偱偼僀儀儞僩偲偟偰 START_ELEMENT 傪巊梡偟傑偟偨偑丄偦偺懠偵傕師偺傛偆側僀儀儞僩偑偁傝傑偡丅
偄偢傟傕 XMLStreamConstants 僋儔僗偱掕媊偝傟偰偄傑偡丅
- START_ELEMENT
- ATTRIBUTE
- NAMESPACE
- END_ELEMENT
- CHARACTERS
- CDATA
- COMMENT
- SPACE
- START_DOCUMENT
- END_DOCUMENT
- PROCESSING_INSTRUCTION
- ENTITY_DECLARATION
- ENTITY_REFERENCE
- NOTATION_DECLARATION
- DTD
偦偟偰丄偪傚偭偲傗偭偐偄側偺偑丄偦傟偧傟偺僀儀儞僩偛偲偵 XMLStreamReader 僋儔僗偺儊僜僢僪偑寛傑偭偰偄傞偲偄偆偙偲偱偡丅徻偟偔偼 XMLStreamReader 僋儔僗偺 Javadoc 傪偛棗偔偩偝偄丅
for 暥傪帺暘偱惂屼偱偒傞偲偄偆偙偲偼丄偡側傢偪僷乕僗傪僐儞僩儘乕儖偱偒傞偲偄偆偙偲偱偡丅偮傑傝丄昁梫側忣曬偑偦傠偭偨傜搑拞偱僷乕僗傪傗傔傞偙偲傕娙扨偩偟丄摿掕偺僞僌傪僗僉僢僾偡傞偺傕娙扨偵彂偗傑偡丅
偱傕丄偙偺傛偆側僗僞僀儖偩偲丄偪傖傫偲僷乕僗傪偟傛偆偲偡傞偲偳偆偟偰傕嫄戝側 if/swintch 暥偑搊応偟偰偟傑偄偑偪偱偡丅偙傟偼偪傚偭偲傗偱偡偹丅
偙傟偑僀儎側恖偼師偺 EventIterator API 傪巊偄傑偟傚偆丅
偲傝偁偊偢僷乕僗 - Event Iterator API 曇
偝偰丄傕偆堦曽偺 Event Iterator API 偱偡丅
Event Iterator API 傕 Cursor API 傕婎杮偼摨偠偱偡丅壗偑堘偆偐偲偄偆偲丄僀儀儞僩偑僆僽僕僃僋僩壔偝傟傞揰偱偡丅
傑偢偼 StAXSample1 僋儔僗偲摨偠偙偲傪 Event Iterator API 傪巊偭偰彂偄偰傒傑偟傚偆丅
| 僒儞僾儖偺僜乕僗僐乕僪 | StAXSample3.java |
|---|
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLEventReader;
import javax.xml.stream.XMLStreamException;
import javax.xml.stream.events.StartElement;
import javax.xml.stream.events.XMLEvent;
public class StAXSample3 {
public StAXSample3(String xmlfile) throws FileNotFoundException, XMLStreamException {
XMLInputFactory factory = XMLInputFactory.newInstance();
BufferedInputStream stream = new BufferedInputStream(new FileInputStream(xmlfile));
XMLEventReader reader = factory.createXMLEventReader(stream);
while (reader.hasNext()) {
XMLEvent event = reader.nextEvent();
if (event.isStartElement()) {
StartElement element = (StartElement)event;
System.out.println("Name: " + element.getName());
}
}
reader.close();
}
public static void main(String[] args) throws FileNotFoundException, XMLStreamException {
new StAXSample3(args[0]);
}
}
Cursor API 偱偼 XMLStreamReader 僋儔僗傪巊梡偟偰偄傑偟偨偑丄Event Iterator API 偱偼 XMLEventReader 僋儔僗傪巊梡偟傑偡丅
惗惉曽朄偼 XMLStreamReader 僋儔僗偲傎傏摨偠偱偡偹丅
XMLEventReader 僆僽僕僃僋僩偑惗惉偱偒偨傜丄儖乕僾偱偡丅愭傎偳偲堘偆偺偼丄僀儀儞僩偑 XMLEvent 僋儔僗偲偟偰尰偝傟偰偄傞揰偱偡丅
XMLEvent 僋儔僗偵偼 isStartElement 儊僜僢僪側偳偺僀儀儞僩偺庬椶傪挷傋傞偨傔偺儊僜僢僪偑偁傞偺偱丄偦傟傪巊偭偰偳偺僀儀儞僩偐挷傋傞偙偲偑偱偒傑偡丅
幚嵺偵偼僀儀儞僩偼僀儀儞僩庬椶偵傛偭偰 XMLEvent 僀儞僞僼僃乕僗偺攈惗僀儞僞僼僃乕僗偱偁傞 StartElement 僀儞僞僼僃乕僗側偳傪巊梡偟偰昞偝傟傑偡丅
偟偐偟丄忋婰偺僐乕僪偩偲 if 暥偑巆偭偨傑傑偱丄偁傑傝 Cursor API 偲堘偄偼偁傝傑偣傫丅偦偙偱丄偙傟傪偮偓偺傛偆偵偟偰傒傑偟偨丅
| 僒儞僾儖偺僜乕僗僐乕僪 | StAXSample4.java |
|---|
public class StAXSample4 {
private Map<Integer, EventHandler> handlers;
public StAXSample4(String xmlfile) throws FileNotFoundException, XMLStreamException {
handlers = initHandlers();
XMLInputFactory factory = XMLInputFactory.newInstance();
BufferedInputStream stream = new BufferedInputStream(new FileInputStream(xmlfile));
XMLEventReader reader = factory.createXMLEventReader(stream);
while (reader.hasNext()) {
XMLEvent event = reader.nextEvent();
EventHandler handler = handlers.get(event.getEventType());
handler.handleEvent(event);
}
reader.close();
}
private Map<Integer, EventHandler> initHandlers() {
Map<Integer, EventHandler> handlers
= new HashMap<Integer, EventHandler>();
handlers.put(XMLEvent.START_ELEMENT, new StartElementHandler());
handlers.put(XMLEvent.END_ELEMENT, new EndElementHandler());
handlers.put(XMLEvent.ATTRIBUTE, new GeneralElementHandler());
handlers.put(XMLEvent.CDATA, new GeneralElementHandler());
handlers.put(XMLEvent.CHARACTERS, new GeneralElementHandler());
handlers.put(XMLEvent.COMMENT, new GeneralElementHandler());
handlers.put(XMLEvent.DTD, new GeneralElementHandler());
handlers.put(XMLEvent.END_DOCUMENT, new GeneralElementHandler());
handlers.put(XMLEvent.ENTITY_DECLARATION, new GeneralElementHandler());
handlers.put(XMLEvent.ENTITY_REFERENCE, new GeneralElementHandler());
handlers.put(XMLEvent.NAMESPACE, new GeneralElementHandler());
handlers.put(XMLEvent.NOTATION_DECLARATION, new GeneralElementHandler());
handlers.put(XMLEvent.PROCESSING_INSTRUCTION, new GeneralElementHandler());
handlers.put(XMLEvent.SPACE, new GeneralElementHandler());
handlers.put(XMLEvent.START_DOCUMENT, new GeneralElementHandler());
return handlers;
}
public static void main(String[] args) throws FileNotFoundException, XMLStreamException {
new StAXSample4(args[0]);
}
}
interface EventHandler {
public void handleEvent(XMLEvent element);
}
class StartElementHandler implements EventHandler {
public void handleEvent(XMLEvent event) {
StartElement element = (StartElement)event;
System.out.println("StartElement: " + element.getName().getLocalPart());
}
}
class EndElementHandler implements EventHandler {
public void handleEvent(XMLEvent event) {
EndElement element = (EndElement)event;
System.out.println("EndElement: " + element.getName().getLocalPart());
}
}
class GeneralElementHandler implements EventHandler {
public void handleEvent(XMLEvent event) {}
}
偙偺僋儔僗偺娞偼僀儀儞僩傪埖偆偨傔偺 EventHandler 僀儞僞僼僃乕僗傪掕媊偟偰丄僀儀儞僩庬椶偛偲偵張棟傪偍偙側偆僋儔僗傪暘偗偨偲偙傠偱偡丅偦傟偧傟偺僆僽僕僃僋僩傪儅僢僾偵偟丄僀儀儞僩庬椶偵傛偭偰偳偺僋儔僗偺 handleEvent 儊僜僢僪傪僐乕儖偡傞偐寛傔傞偙偲偑偱偒傑偡丅
僀儀儞僩僴儞僪儔偱偺僉儍僗僩偑偪傚偭偲婥偵側傞偺偱偡偑丄if 暥偼徚偡偙偲偑偱偒傑偟偨丅
偙偆偄偆偙偲偑偱偒傞偺傕丄僀儀儞僩傪僆僽僕僃僋僩偲偟偰埖偆偙偲偑偱偒傞偐傜偱偡丅
偟偐偟丄栤戣傕偁傝傑偡丅
僴儞僪儔傪奿擺偟偰偍偔 Map 僆僽僕僃僋僩偵偼丄張棟傪偡傞僀儀儞僩偩偗偱側偔懠偺僀儀儞僩偵娭偟偰傕僴儞僪儔傪懳墳晅偗偰偍偐側偔偰偼偄偗側偄偲偄偆偙偲偱偡丅壗傕偟側偄偺偵丄僐乕僪偩偗偼挿偔側偭偰丄曐庣惈偑埆偔側偭偰偟傑偄傑偡丅
偦偆偄偆梡搑偺偨傔偵僀儀儞僩偺僼傿儖僞乕偑 StAX 偵偼梡堄偝傟偰偄傑偡丅丅
| 僒儞僾儖偺僜乕僗僐乕僪 | StAXSample5.java |
|---|
public class StAXSample5 {
private Map<Integer, EventHandler> handlers;
public StAXSample5(String xmlfile) throws FileNotFoundException, XMLStreamException {
handlers = initHandlers();
XMLInputFactory factory = XMLInputFactory.newInstance();
BufferedInputStream stream = new BufferedInputStream(new FileInputStream(xmlfile));
XMLEventReader reader = factory.createXMLEventReader(stream);
EventFilter filter = new EventFilter() {
public boolean accept(XMLEvent event) {
return event.isStartElement() || event.isEndElement();
}
};
reader = factory.createFilteredReader(reader, filter);
while (reader.hasNext()) {
XMLEvent event = reader.nextEvent();
EventHandler handler = handlers.get(event.getEventType());
handler.handleEvent(event);
}
reader.close();
}
private Map<Integer, EventHandler> initHandlers() {
Map<Integer, EventHandler> handlers
= new HashMap<Integer, EventHandler>();
handlers.put(XMLEvent.START_ELEMENT, new StartElementHandler());
handlers.put(XMLEvent.END_ELEMENT, new EndElementHandler());
return handlers;
}
public static void main(String[] args) throws FileNotFoundException, XMLStreamException {
new StAXSample5(args[0]);
}
}
interface EventHandler {
public void handleEvent(XMLEvent element);
}
class StartElementHandler implements EventHandler {
public void handleEvent(XMLEvent event) {
StartElement element = (StartElement)event;
System.out.println("StartElement:"" + element.getName().getLocalPart());
}
}
class EndElementHandler implements EventHandler {
public void handleEvent(XMLEvent event) {
EndElement element = (EndElement)event;
System.out.println("EndElement: " + element.getName().getLocalPart());
}
}
愒帤偺偲偙傠偑僼傿儖僞乕偱偡丅
僼傿儖僞乕偵偼 EventFilter 僀儞僞僼僃乕僗傪巊梡偟傑偡丅EventFilter 僀儞僞僼僃乕僗偼 accept 儊僜僢僪傪掕媊偟偰偄傑偡丅偙偺 accept 儊僜僢僪偱丄僷乕偡偡傞僀儀儞僩偼 true 傪曉偟丄偦傟埲奜偼 false 傪曉偡傛偆偵偟傑偡丅
僼傿儖僞乕傪嶌惉偟偨傜丄XMLInputFactory 僋儔僗偺 createFilteredReader 儊僜僢僪傪巊梡偟偰丄傕偆 1 搙 XMLEventReader 僆僽僕僃僋僩傪嶌傝捈偟傑偡丅
偙傟偩偗偱丄愭傎偳傑偱偁偭偨挿偄 Map 僆僽僕僃僋僩偺弶婜壔僐乕僪偑側偔側傝傑偟偨丅偨偩丄僼傿儖僞乕偵 if 暥偑擖偭偰偟傑偭偰偄傞偺偱丄偪傚偭偲婥偵側傞偺偱偡偑丅偙傟偼偪傚偭偲岺晇偡傟偽 if 暥傪巊傢側偄偱彂偗傞偼偢側偺偱丄嫽枴偑偁傞曽偼挧愴偟偰傒偰偔偩偝偄丅
偝偰丄StAX 偺 2 庬椶偺僷乕僗傪尒偰偒偨傢偗偱偡偑丄SAX 偵斾傋偰娙扨偩偲巚偄傑偣傫偐丅
SAX 傪巊偭偰偄偰壗偑偄傗偐偲偄偆偲丄忬懺傪曐帩偟偰偍偐側偄偲偄偗側偄偙偲偱偡丅StAX 偱偼 State 僷僞乕儞傗 Strategy 僷僞乕儞傪巊偆偙偲偱忬懺傪曐帩偣偢偵僷乕僗傪恑傔偰偄偔偙偲偑壜擻偱偡丅
偙傟偩偗偱傕丄巹偼巊偄偑偄偑偁傞偲姶偠偰偄傞偺偱偡偑丄偄偐偑偱偡偐?
偱傕丄StAX 偼偦傟偩偗偱偼側偄偺偱偡丅
XML 偺嶌惉 - Cursor API 曇
側傫偲 StAX 偱偼 XML 偺嶌惉傕偱偒偰偟傑偆偺偱偡丅
偙傟傪巊偄弌偡偲 DOM 側傫偐巊偭偰偄傜傟側偄偱偡傛丅
XML 偺嶌惉傕 Cursor API 偲 Event Iterator API 偵暘偐傟偰偄傑偡丅傑偢偼丄Cursor API 偱 XML 傪嶌偭偰傒傑偟傚偆丅
| 僒儞僾儖偺僜乕僗僐乕僪 | StAXSample6.java |
|---|
import java.io.StringWriter;
import javax.xml.stream.XMLOutputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamWriter;
import javax.xml.stream.XMLStreamException;
public class StAXSample6 {
public StAXSample6() throws XMLStreamException {
XMLOutputFactory factory = XMLOutputFactory.newInstance();
StringWriter stringWriter = new StringWriter();
XMLStreamWriter writer = factory.createXMLStreamWriter(stringWriter);
System.out.println("XML: " + stringWriter);
writer.writeStartDocument();
System.out.println("XML: " + stringWriter);
writer.writeDTD("<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\" "
+ "\"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\">");
System.out.println("XML: " + stringWriter);
writer.writeStartElement("html");
System.out.println("XML: " + stringWriter);
writer.writeDefaultNamespace("http://www.w3.org/1999/xhtml");
System.out.println("XML: " + stringWriter);
writer.writeEndElement();
System.out.println("XML: " + stringWriter);
writer.writeEndDocument();
System.out.println("XML: " + stringWriter);
writer.close();
}
public static void main(String[] args) throws XMLStreamException {
new StAXSample6();
}
}
僷乕僗偼 XMLInputFactory 僋儔僗偱偟偨偑丄XML 偺嶌惉偱偼 XMLOutputFactory 僋儔僗傪巊梡偟傑偡丅
偦偟偰丄XMLOutputFactory#createXMLStreamWriter 儊僜僢僪傪巊梡偟偰 XMLStreamWriter 僆僽僕僃僋僩傪惗惉偟傑偡丅
偙偺 XMLStreamWriter 僋儔僗偑 XML 偺惗惉傪偍偙側偄傑偡丅
XMLStreamWriter 僋儔僗偵偼 writeStartDocument 儊僜僢僪傗 writeStartElement 儊僜僢僪偲偄偭偨儊僜僢僪偑掕媊偝傟偰偄傞偺偱丄偙傟傜傪弴偵僐乕儖偡傞偙偲偱 XML 傪嶌惉偟傑偡丅
幚峴偟偨傜偳偆側傞偱偟傚偆偐丅
C:\temp>java StAXSample6 stax.html XML: XML: <?xml version=":1.0": ?> XML: <?xml version=":1.0": ?><!DOCTYPE html PUBLIC ":-//W3C//DTD XHTML 1.0 Transiti onal//EN": ":http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd":> XML: <?xml version=":1.0": ?><!DOCTYPE html PUBLIC ":-//W3C//DTD XHTML 1.0 Transiti onal//EN": ":http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd":><html XML: <?xml version=":1.0": ?><!DOCTYPE html PUBLIC ":-//W3C//DTD XHTML 1.0 Transiti onal//EN": ":http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd":><html xmlns= ":http://www.w3.org/1999/xhtml": XML: <?xml version=":1.0": ?><!DOCTYPE html PUBLIC ":-//W3C//DTD XHTML 1.0 Transiti onal//EN": ":http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd":><html xmlns= ":http://www.w3.org/1999/xhtml":></html> XML: <?xml version=":1.0": ?><!DOCTYPE html PUBLIC ":-//W3C//DTD XHTML 1.0 Transiti onal//EN": ":http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd":><html xmlns= ":http://www.w3.org/1999/xhtml":></html>
XML 僪僉儏儊儞僩偑彊乆偵偱偒偁偑偭偰偄偔條巕偑偍暘偐傝偱偟傚偆偐丅暋悢峴偵暘偐傟偰偄傞偺偼僐儅儞僪僾儘儞僾僩偺昞帵偺偨傔偱丄幚嵺偵偼 1 峴偵彂偐傟偰偄傞傛偆偱偡丅
StAX 偱偼 XMLStreamWriter 僋儔僗傪巊梡偟偰丄偳傫偳傫 XML 傪彂偒弌偟偰偄偒傑偡丅偮傑傝丄DOM 偺傛偆偵儊儌儕偵書偊偙傑側偄傢偗偱偡丅偲偄偆偙偲偼丄巊梡儊儌儕傕掅偔梷偊傜傟傞偲偄偆棙揰偑偁傝傑偡偹丅
XML 偺嶌惉 - Event Iterator API 曇
師偼 Event Iterator API 傪巊梡偟偰丄XML 傪嶌惉偟偰傒傑偡丅
僷乕僗偺帪偲摨偠傛偆偵 Event Iterator API 偱偼丄僀儀儞僩傪僆僽僕僃僋僩偲偟偰埖偄傑偡丅
StAXSample6 僋儔僗偲摨偠 XML 傪惗惉偡傞僒儞僾儖傪嶌偭偰丄椉幰傪斾妑偟偰傒傑偟傚偆丅
| 僒儞僾儖偺僜乕僗僐乕僪 | StAXSample7.java |
|---|
public StAXSample7() throws XMLStreamException {
XMLOutputFactory factory = XMLOutputFactory.newInstance();
StringWriter stringWriter = new StringWriter();
XMLEventWriter writer = factory.createXMLEventWriter(stringWriter);
XMLEventFactory eventFactory = XMLEventFactory.newInstance();
System.out.println("XML: " + stringWriter);
writer.add(eventFactory.createStartDocument());
System.out.println("XML: " + stringWriter);
writer.add(eventFactory.createDTD("<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\" "
+ "\"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\">"));
System.out.println("XML: " + stringWriter);
writer.add(eventFactory.createStartElement("", "http://www.w3.org/1999/xhtml", "html"));
System.out.println("XML: " + stringWriter);
writer.add(eventFactory.createNamespace("http://www.w3.org/1999/xhtml"));
System.out.println("XML: " + stringWriter);
writer.add(eventFactory.createEndElement("", "http://www.w3.org/1999/xhtml", "html"));
System.out.println("XML: " + stringWriter);
writer.add(eventFactory.createEndDocument());
System.out.println("XML: " + stringWriter);
writer.close();
}
偩偄偨偄偍暘偐傝偩偲巚偄傑偡偑丄弌椡傪偍偙側偆偺偼 XMLEventWriter 僋儔僗偱偡丅
XMLEventWriter 僋儔僗偵偼 add 儊僜僢僪偑掕媊偝傟偰偍傝丄XMLEvent 僆僽僕僃僋僩傪堷悢偵偲傝傑偡丅
偙偙偱丄僀儀儞僩僆僽僕僃僋僩傪搉偡傢偗偱偡偑丄僀儀儞僩傪枅夞嶌傞偺傕柺搢偱偡丅偦傫側偲偒偺偨傔偵丄XMLEventFactory 僋儔僗傪巊偆偙偲偑偱偒傑偡丅偙偺僋儔僗偵偼 createStartDocument 儊僜僢僪傗 createStartElement 儊僜僢僪偺傛偆偵丄嶌惉偡傞僀儀儞僩偵懳墳偟偨儊僜僢僪偑掕媊偟偰偁傝傑偡丅
偙傟傜偺儊僜僢僪傪巊梡偟偰僀儀儞僩傪嶌惉偟丄XMLEventWriter#add 偺堷悢偵偡傞傢偗偱偡丅
偍傑偗
幚傪偄偆偲 StAX 偼偡偱偵 JWSDP 偵娷傑傟偰偄傑偡丅
偱偡偐傜丄JWSDP 偺僪僉儏儊儞僩側偳偱偦偺柤慜偼尒偨偙偲偑偁傞恖偑寢峔偄傞偺偱偼側偄偱偟傚偆偐丅
偱傕丄巊傢傟偰偄偨偐偳偆偐偲側傞偲偐側傝媈栤晞偑偮偒傑偡丅儊僨傿傾偱庢傝忋偘傜傟傞偙偲傕彮側偄偟丄Web 偱専嶕偟偰傕偁傑傝堷偭偐偐傝傑偣傫丅
偱傕丄偦傟偼偁傑傝偵傕傕偭偨偄側偄丅
嫄戝側 XML 僪僉儏儊儞僩傪埖偆偲偒偲偐丄XML 僪僉儏儊儞僩偺堦晹偟偐巊傢側偄偲偐丄XML 僪僉儏儊儞僩嶌惉偟偨偄偲偐丄偄傠偄傠側梡搑偱 StAX 偼桳岠偱偡丅
偤傂丄偙偺婡夛傪摝偝偢偵 StAX 傪巊傢傟偰傒偨傜偄偐偑偱偟傚偆偐丅
嶲峫
JSR-173 Streaming API for XML
Paul R. Brown, "StAX 偺儀乕儖傪攳偖", JavaPress 2004.5
(Nov. 2005)